Explicar el concepto de Big Data puede resultar sencillo a simple vista, pero nada más lejos de la realidad. Aunque, en esencia, es tan solo la captación de enormes cantidades de datos…, ¿por qué se habla ahora de Big Data?, ¿ninguna empresa hacía esto antes? La respuesta es si, de hecho, la mayoría de las empresas lo hacían, pero no de la misma manera.
Para entender esto hay que pensar en los grandes avances de la tecnología en las dos últimas décadas, sobre todo en el sector de las TIC. La cantidad de información que se puede almacenar es mucho mayor y se puede procesar mucho más rápido. El número de dispositivos conectados ha aumentado y cuentan con funcionalidades más avanzadas. Estamos rodeados de sensores de todo tipo que son capaces de captar enormes cantidades de datos de manera casi instantánea.
Debido a su volumen, toda esta información no puede ser tratada de manera convencional. Se han creado infraestructuras y herramientas específicas para ello. El principal objetivo de la toma de datos no es otro que facilitar la toma de decisiones sobre un producto o negocio, pero también como base de una investigación, etc.
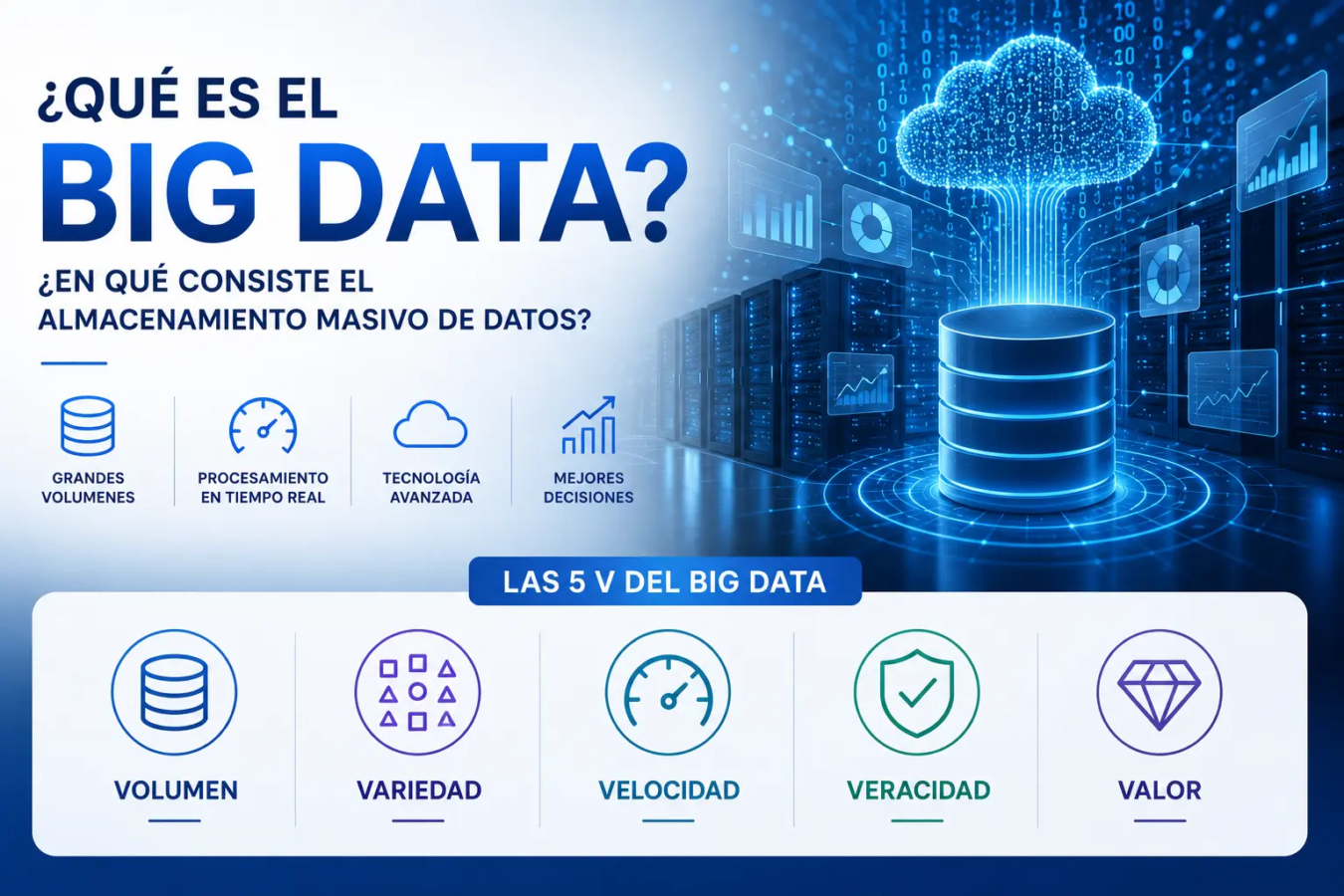
Las 5 Vs del Big Data
Para realizar un correcto tratamiento de los datos, habrá que tener en cuenta las características especiales del Big Data, o lo que muchos llaman «las Vs». Unos dirán que son 3, otros 4, 5, 7… Lo único cierto es que crecen a cada momento, y mucho me temo, que más pronto que tarde, se acabarán las palabras con V. En esta clasificación he querido reflejar las 5 que me parecen más importantes, aunque estad seguros de que a medida que se profundiza en el tema, da para mucho más.
Volumen
La cantidad de información que se almacena es cada vez mayor, crece de manera exponencial y es el principal valor del Big Data. Si antes con unas muestras, más o menos representativas, valía para obtener una estadística, ahora eso no basta. Se procesan cada vez más datos y de maneras más dispares. En vez de tomar un porcentaje de los datos para analizarlos, se tiende a tomar el 100%.
Variedad
Como hemos comentado antes, la enorme variedad de formas con las que se puede captar la información, provoca que haya datos estructurados, semi-estructurados y no estructurados. No podemos tratarlos de la misma manera, y requerirán de una tecnología diferente. Habrá que tener especial cuidado, pues los datos no estructurados, si no se interpretan bien, pueden producir grandes desviaciones en el resultado.
Velocidad
Que los datos se traten de manera inmediata, y los podamos interpretar en tiempo real, es uno de los mayores potenciales del Big Data. Si los captáramos sin analizarlos, no serviría de nada, y si esperáramos a tenerlos todos, nunca acabaríamos. Este proceso se tiene que realizar de manera simultánea para que el sistema funcione. Nos permite adquirir capacidades predictivas que conllevan una gran ventaja.
Veracidad
Una de las características más difíciles de cumplir en los análisis de datos es la veracidad. Eliminar los datos tomados de manera incorrecta y detectar patrones reales es todo un reto del Big Data. Si anteriormente decíamos que se trataba de almacenar la totalidad de los datos disponibles, también hay que decir, que una vez almacenados, no todos tienen la misma validez. Las múltiples variables y situaciones en las que se han tomado los datos, pueden haber provocado cambios imprevisibles que modifiquen la información. Separar el trigo de la paja es una tarea imprescindible que nos permitirá obtener un resultado con mayores probabilidades de éxito.
Valor
Este concepto es muy parecido a la veracidad. La diferencia está en que su estudio se realiza antes de la captación de información. Tan importante es la veracidad de los datos, como que los datos tomados aporten valor. Por lo tanto, antes de la toma de datos, habrá que investigar cuales son los que nos van a aportar ese valor necesario. Posteriormente es cuando se analizará su veracidad.